Unicode используется почти на 50% веб-сайтов
Около 18 месяцев назад мы опубликовали график, показывающий, что доля Unicode недавно превысила долю всех других кодировок текста в Интернете. С тех пор рост стал ещё более впечатляющим.
Веб-страницы могут использовать различные кодировки, например, ASCII, Latin-1, Windows 1252 или Unicode. Большинство кодировок может использоваться только для нескольких языков, но Unicode применим для тысяч языков: от арабского до китайского или зулу. Мы уже давно используем Unicode в качестве внутреннего формата всех текстов, используемых в нашем поисковом индексе: любые другие кодировки сначала преобразуются в Unicode.
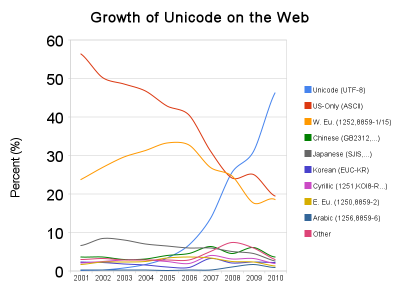
Этот график построен по внутренним данным Google, собираемых при индексировании веб-страниц, и может несколько отличаться от данных других поисковых систем. Тем не менее, тенденции довольно ясны, и продолжающийся рост использования Unicode приведет к более простой обработке всех языков, используемых на веб-страницах.
Unicode растет как в масштабе использовании, так и в характере охвата символов. Недавно наши сервисы были обновлены до последней версии Unicode, 5.2 (с помощью ICU — International Components for Unicode и CLDR — Unicode Common Locale Data Repository). При этом было добавлено свыше 6600 новых символов: некоторые представляющие большой академический интерес, например, египетские иероглифы, но большинство других для "живых" языков.
После тщательного тестирования, мы совсем недавно включили поддержку для этих и тысяч других символов; теперь вы сможете найти ещё больше документов с помощью Google. Наша миссия — организовать всемирную информацию и сделать её всесторонне доступной и полезной.
Новость основана на публикации "Unicode nearing 50% of the web".